Crawl
Crawl
Added List Crawl
When crawling, some settings must be done, which requires knowledge of HTML and CSS. Click the add button on the right side, fill in the requirements, and click the submit button to save the settings.
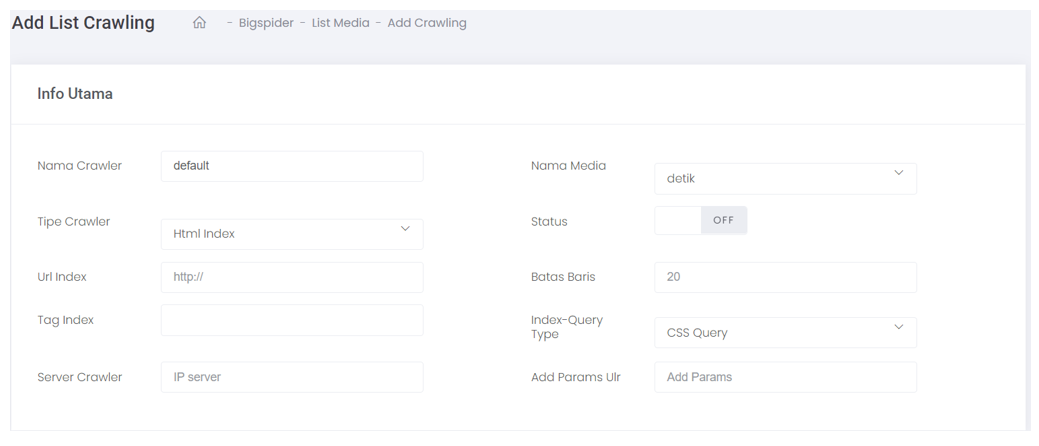
- Some of the data fields that must be completed are as follows :
- Url index, which must be completed, is the website address of the related media (URL)
- The index tag is done by reading the code from the related media URL (inspecting)
- Crawler server, the IP address of the server used for crawling
- Media Name, the name of the media to be crawled
- Status, to activate the settings to be added
- Line Limit, parameter to retrieve news count
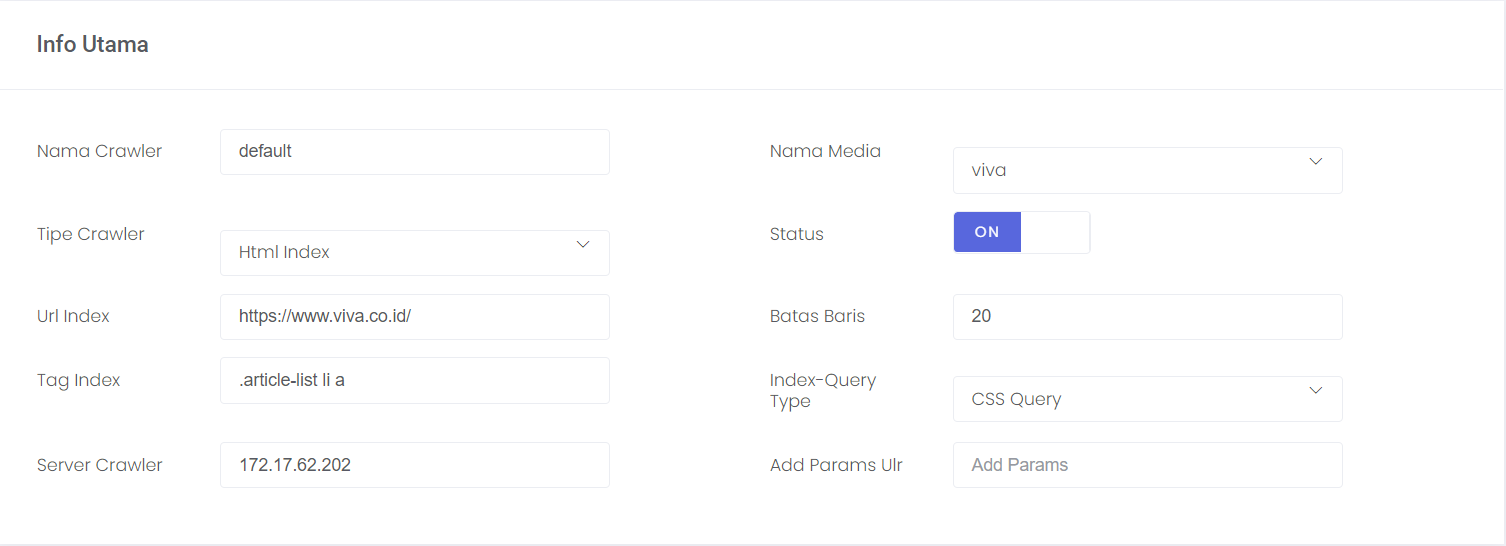
The following is an example of media settings that will be crawled.
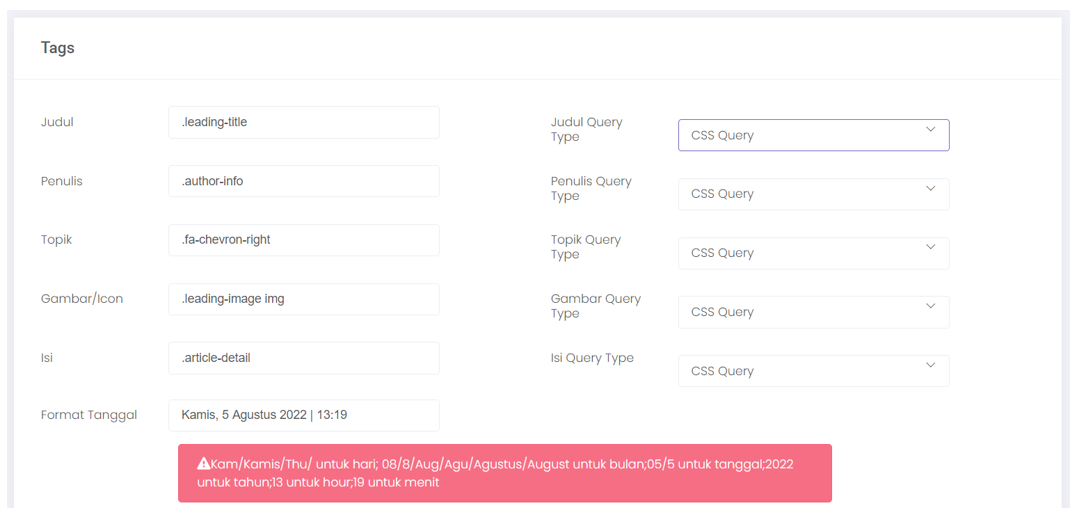
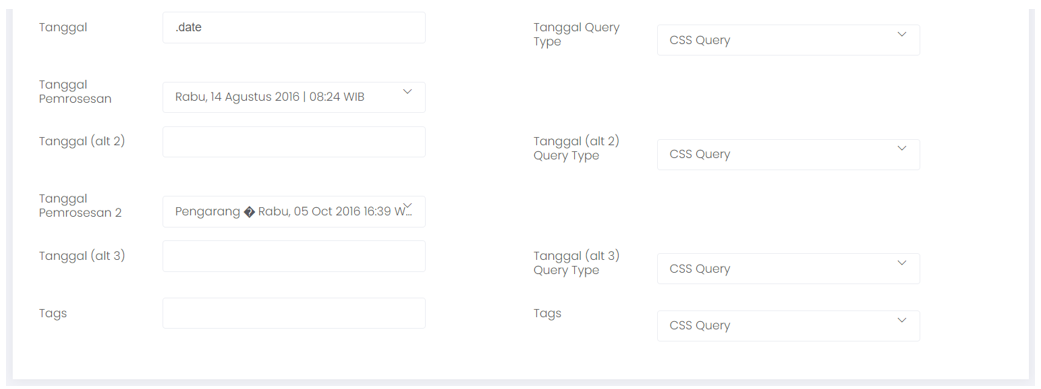
- To display data in more detail, it is necessary to fill in the data entry requirements in the tag menu by adjusting the code on the related media website page.
- Title, to display the title of the news/post from the media.
- Author, to display the author of the news/post.
- Topic, to display the topic of the news/post.
- Image/icon, to display news/post /img/bigspider/images/en/.
- Contents to display news/post content.
- Date format, determine the layout of writing the date and then adjust to the existing writing on BigSpider.
- Date, to display a description of the date in the news/post.
The following is an example of the settings that have been made.
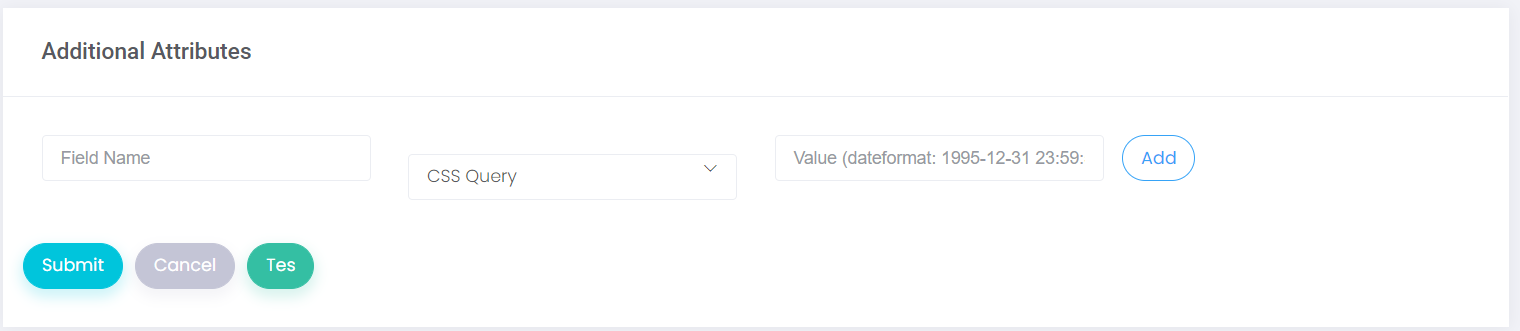
- After the data entry requirements have been filled in, the test results can be tested to ensure that the settings have been running correctly. Click the test button at the bottom, and the system will automatically retrieve data according to the grounds.
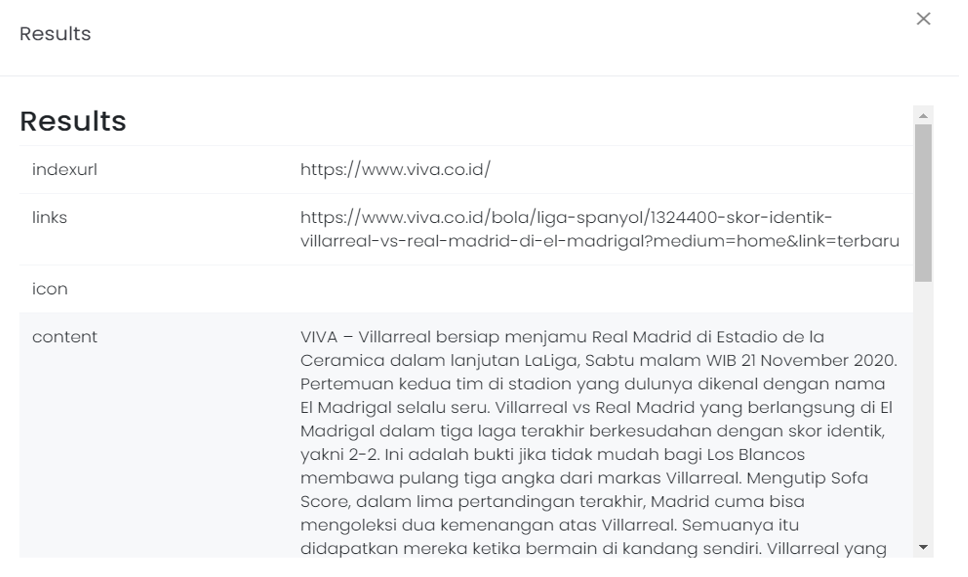
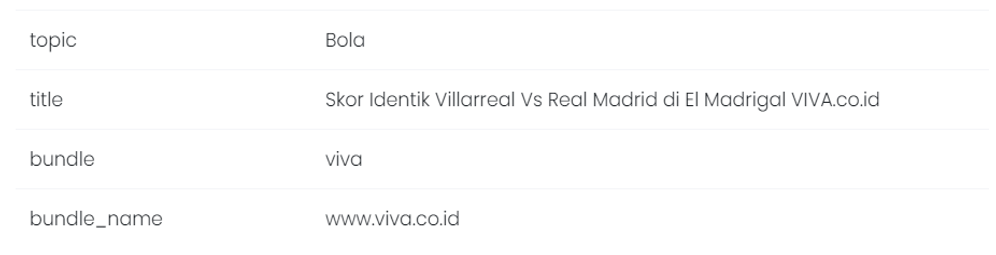
The following are the test results of the settings that have been made.
Searching
The searching feature can be used for media searches.
Actions
BigSpider media list management has two features that can be used in media settings, namely Editing Media and deleting existing Media lists.